KI benötigt viele Daten für ein Training, das wisse doch jedes Kind, so heißt es. Oft wird dabei aber nicht ausreichend beleuchtet, dass es verschiedene KI-Ansätze gibt und nicht jeder Anwendungsbereich diesen erwähnten Anlernprozess benötigt.
Überwachtes maschinelles Lernen (Supervised Machine Learning)
Mit KI wird oft das System des überwachten maschinellen Lernens gemeint. Hierbei handelts es sich um eine Verfahrensweise, die mit zwei Algorithmen arbeitet. Der erste Algorithmus ist der Lernalgorithmus selbst, zu diesen zählen beispielsweise der k-nächste-Nachbarn-Algorithmus, Entscheidungsbaumverfahren auf Basis des ID3-Algorithmus oder die als Deep Learning bezeichneten Verfahren der künstlichen neuronalen Netze. Diese Verfahren können wiederum in parametrisierte und nicht-parametrisierte Verfahren unterschieden werden. Der Lernalgorithmus erstellt ein Prädiktionsmodell, also ein Modell, dass bei gegebenen Input ein bestimmten Zielwert erkennt. Dieser Zielwert muss während des Training-Vorgangs vorgegeben werden, daher spricht man von einer gekennzeichneten Datenhistorie (labeled data). Der Lernalgorithmus erstellt das Model auf Basis dieser Trainingsdaten. Das Modell ist der zweite Algorithmus des überwachten maschinellen Lernens und ist im Grunde eine Formel, die bei gegebenen Input den Output vorhersagt.
Der Lernprozess kann dabei die Struktur der Formel selbst bestimmen (z. B. die Form des Entscheidungsbaumes) oder instanzbasierte Entscheidungen treffen (z. B. über k-nächste-Nachbarn-Vergleichsabfragen), beides ist das nicht-parametrisierte Lernverfahren (non-parametric learning). Eine nur kleine Änderung in den Trainingsdaten kann so zu einer ganz neuen Entscheidungsgrundlage im Modell führen.
Der Lernprozess kann jedoch auch über eine feste Formel erfolgen, beim parametrisierten maschinellen Lernen (Parametric Machine Learning). Dies bedeutet, dass die Struktur der Prädiktion y für eine Reihe an x-Werten vorgegeben ist und nur die Werte der Variablen (Faktoren der x-Werte) über den Lernprozess gebildet werden. Diese Variablen sind die sogenannten Parameter des Models, für die die Werte bestimmt werden. Die meisten Verfahren im Deep Learning sind parametrisiert, hier ist die Struktur (Architektur) des neuronalen Netzes mit allen Neuronen der Eingabe- und Ausgabe- sowie der verborgenen Schichten (Hidden Layer) vorgegeben, lediglich die Gewichtungen (Verbindungen) zwischen den Neuronen müssen für die Zielausrichtung des Prädiktion antrainiert – dafür die Werte definiert – werden.
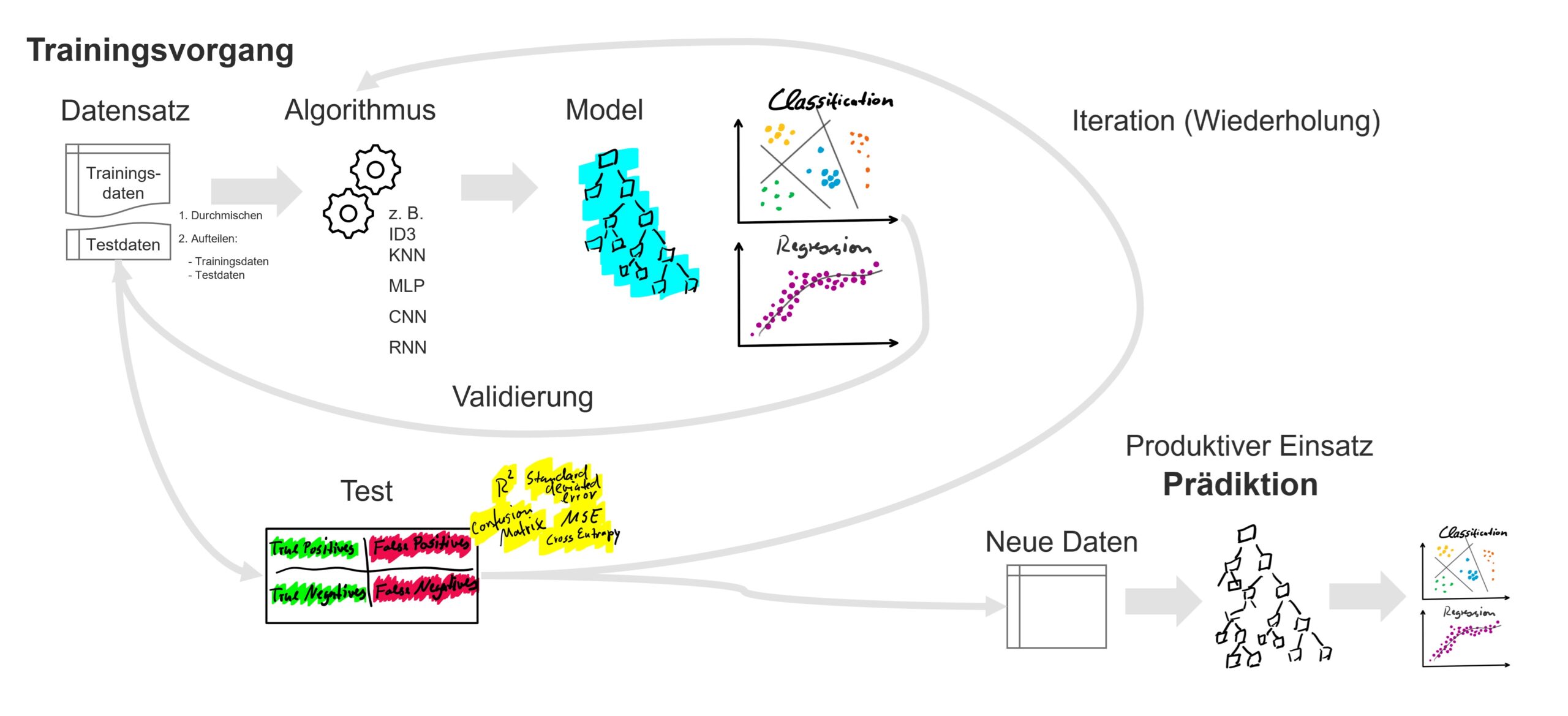
Supervised Machine Learning ist die Grundlage für die meisten KI-Anwendungen.
Voraussetzungen für überwachtes maschinelles Lernen:
- Es muss eine Datenhistorie vorliegen, die mit Zielwerten gekennzeichnet ist.
- Der Trainingsprozess benötigt viele Daten und somit große Speicher- und Rechenkapazitäten.
- Die Daten müssen entsprechend der Zielvorgabe aufbereitet und möglichst bereinigt sein.
- Die Validierung der Prädiktion muss erfolgen und das auf Basis von Daten, mit denen der Lernalgorithmus nicht trainiert worden ist.
Anwendungsbeispiele für überwachtes maschinelles Lernen:
- Forecasting von Geschäftsereignissen (z. B. Bestellungen / Bestellmengen), Warenbeständen und Finanzdaten.
- Beurteilung von Geschäftsrisiken (z. B. für Finanztransaktionen oder Ausfallrisiken bzgl. Kunden, Lieferanten oder Maschinen).
- Vorhersage bester Marketing-Kanäle oder lohnenswerter Verkaufsaktivitäten.
- Erkennung von wichtigen Begriffen und Kontexten in Text- oder Bilddaten, z. B. zur Extraktion von Informationen aus Rechnungen, E-Mails oder Bildern.
Kritische Faktoren und Fähigkeiten für den Erfolg mit überwachtem maschinellen Lernen:
- Richtige Vorbereitung der Trainingsdaten mit Auswahl der richtigen Attribute (Feature Engineering) und richtige Aufteilung der Daten in Trainings- und Testdaten.
- Richtige Auswahl der Lernalgorithmen oder Zusammenstellung (Ensemble Learning).
- Fähigkeit der Validierung und Beurteilung der Prädiktionsalgorithmen
Oftmals unterschätzen gerade unerfahrene Data Scientists den Punkt der Validierung von Modellen. Erfahrene Data Scientists wissen: Zuerst wird das Verfahren der Validierung definiert, erst danach der Lernalgorithmus ausgewählt. Und für Regression reicht R² als Kriterium alleine nicht aus.
Eine Abwandlung des supervised Machine Learning ist das bestärkende Lernen (Reinforcement Learning), das noch granularer im Training funktioniert und statt einer Datenhistorie eine interaktive Umgebung benötigt, die für jede Aktion ein Feedback liefert, aus dem gelernt wird.
Unüberwachtes maschinelles Lernen (Unsupervised Machine Learning)
Unüberwachtes maschinelles Lernen ist ein gänzlich anderer Ansatz des Machine Learnings und ist – abgekürzt erläutert – das echte Data Mining. Denn Unsupervised Machine Learning tut genau das, was als Data Mining bezeichnet wird: Die Extraktion von Strukturen in beliebig großen und vielfältigen Datenmengen. Es bietet Insights (Einblicke) für den Nutzer (Betrachter), jedoch unter der Voraussetzung, dass Strukturen in Daten bestehen und dass der menschliche Nutzer diese auch in den Resultaten erkennen und interpretieren kann.
Ein Anwendungsbeispiel im Handel / eCommerce ist die Analyse von Kundenverhaltensgruppen auf einer Shop-Webseite. Sicherlich gibt es unterschiedlichen Kundengruppen, die unterschiedliche Art und Weisen an den Tag legen, den Shop zu nutzen. Dabei können Daten-Dimensionen wie die Klick-Rate und die zuerst besuchten Produkte sowie viele weitere Dimensionen eine Rolle spielen. Zwar können die Kunden bereits in logische Gruppen eingeteilt werden (z. B. nach Lokation, Geschlecht, Alter), wenn bekannt, aber Verhaltensmuster zeigen sich oft besonders zwischen diesen Dimensionen. Clustering ist hierfür eine Lösungen, diese Gruppierungen in multi-dimensionalen Räumen zu erkennen und ist somit für viele Anwendungsszenarien die Vorstufe vor der Klassifikation (Supervised ML). Denn Clustering (z. B. mit K-Means oder DBSCAN-Clustering) bildet Gruppierungen, die – wenn durch den Nutzer als relevant und hilfreich festgelegt – dann zu Klassen werden. Ein überwachtes maschinelles Lernverfahren kann dann weitere Shop-Besucher diesen Klassen zuordnen.
Ein Anwendungsbeispiel für Dimensionsreduktion ist die Visualisierung der Verteilung von mehr-dimensionalen Daten, dadurch werden mit linearen (z. B. Hauptkomponentenanalyse / PCA) oder nicht-linearen (z. B. t-SNE) Verfahren neue Dimensionen zwischen den ursprünglichen Dimensionen erstellt. Diese neuen Zwischendimensionen können dann ihrer Bedeutung (nach Informationsdichte hinsichtlich der Verteilung) nach sortiert und auf die wichtigsten reduziert werden. Die zwei bis drei relevantesten Dimensionen lassen sich dann für den menschlichen Betrachter visualisieren, sind jedoch wiederum kaum zu interpretieren, da diese Dimensionen selbst aus verschiedenen ursprünglichen Dimensionen erstellt wurden. Jedoch sind diese Dimensionen oftmals sehr hilfreich als Grundlage (Features) für überwachte Lernverfahren. Also auch hier wird unsupervised ML zur Vorstufe (Vorbereitung) für supervised ML. Dimensionsreduktion wird besonderes häufig bei Maschinensensordaten angewendet, auch weil diese Daten-Dimensionen in ihrer ursprünglichen Form meistens so groß und vielfältig sind, dass sie für den Menschen schlecht zu verstehen sind.
Ein leicht zugängliches Anwendungsbeispiel ist die Anomalieerkennung, die beispielsweise oft in Bestell-, Finanz- und auch Maschinendaten angewandt wird. Anomalien müssen kein Problem darstellen, deuten jedoch auf die Möglichkeit des Vorliegens von Problemen hin. Diese Interpretation muss durch den Menschen erfolgen und die Anomalie-Extraktion dahingehend optimiert werden, den notwendigen Interpretationsaufwand zu verringern.
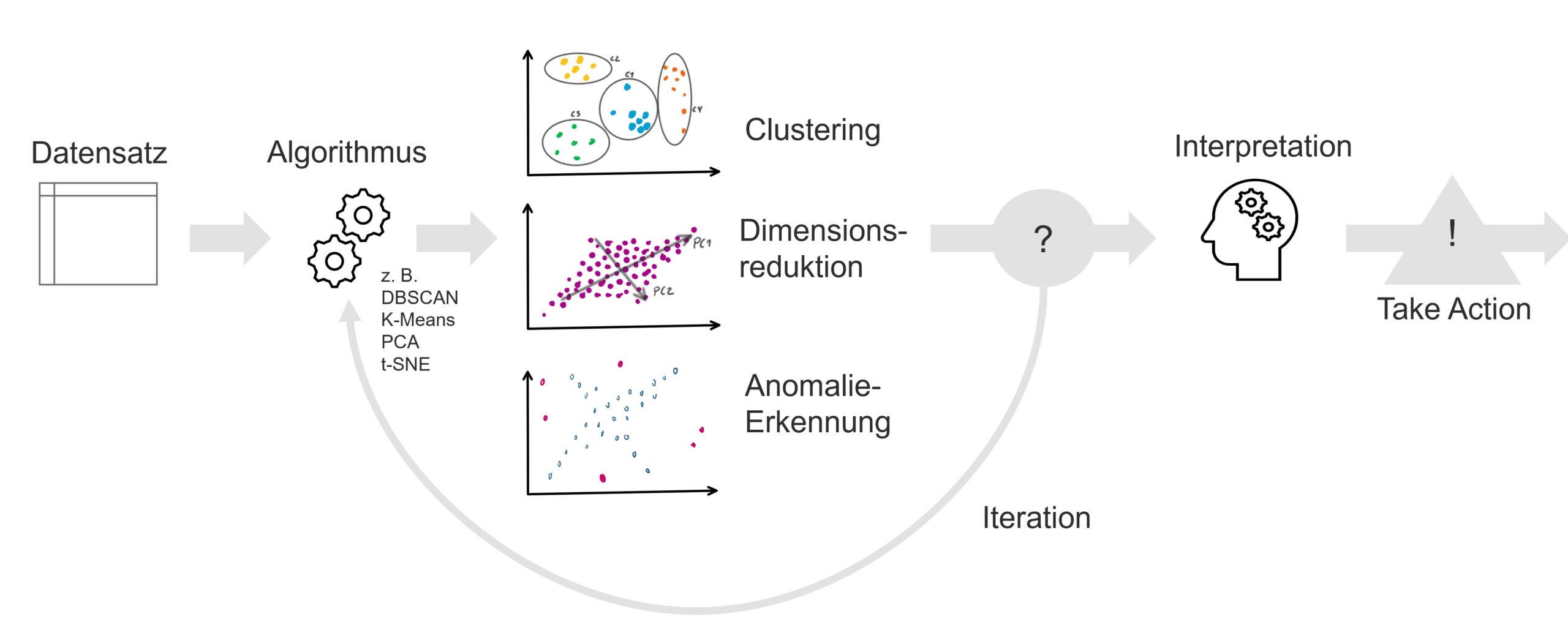
Voraussetzungen für unüberwachtes maschinelles Lernen:
- Der Anwender muss eine grundsätzliche Idee davon haben, welche Insights von der Anwendung des unsupervised Machine Learning zu erwarten sind.
- Der Anwender muss die Ergebnisse der Algorithmen interpretieren und ideale Hyperparameter (z. B. besten K-Wert für K-Means) finden können.
Anwendungsbeispiele für unüberwachtes maschinelles Lernen:
- Finden von Gruppierungen (Cluster) in Daten, z. B.
- in Kunden- und Bestelldaten, um Forecasts bessere auf jede Gruppe trainieren zu können oder
- in Maschinen-Fehler-Daten, um unterschiedliche Ausfall- und Fehler-Szenarien in Fabriken und Maschinen zu identifizieren.
- Aufspüren von Anomalien in Daten, z. B.
- in Maschinendaten, um Anomalien in Produktionslinien frühzeitig zu erkennen oder
- in Finanzdaten, um ungewöhnliche Buchungen oder Buchungsmuster zu erkennen.
- Reduktion von Dimensionen, z. B.
- zur Vorbereitung und Verbesserung des Trainings überwachten maschinellen Lernverfahren durch weniger Dimensionen, die jedoch gleichermaßen höhere Informationsdichte bieten oder
- zur Visualisierung von mehrdimensionalen Daten, reduziert in neuen-zwischendimensionalen neuen Dimensionen.
Beispielsweise nutzt das Unternehmen AUDAVIS unüberwachtes maschinelles Lernen, um Anomalien in Finanztransaktionen bzw. Buchungsdaten zu finden. Diese Anomalien müssen keinesfalls ein Finding für den Wirtschaftsprüfer oder internen Revisor darstellen, jedoch sind jede Anomalien eine mathematische Abweichung von einem Verhaltensstandard innerhalb einer Buchungsdaten-Population und somit für den Prüfer interessant.
Kritische Faktoren und Fähigkeiten für den Erfolg mit unüberwachtem maschinellen Lernen:
- Richtige Vorbereitung der zu untersuchenden Daten mit Auswahl der richtigen Attribute (Feature Engineering).
- Richtige Auswahl der Algorithmen oder Zusammenstellung dieser zu einem Ensemble (z. B. Anomalie-Erkennung mit Kombination aus mehreren Algorithmen).
- Fähigkeit der Validierung und Beurteilung der Ergebnisse, insbesondere auch die Findung des optimalen Hyperparameter-Konfiguration.
Fazit – Supervised oder Unsupervised?
Diese Frage erübrigt sich nun für den aufmerksamen Leser, denn diese zwei unterschiedlichen Verfahrensweisen stehen keinesfalls im Konkurrenz zueinander, sondern ergänzen sich. Unüberwachte Verfahren des Machine Learning sind Ansätze des Data Minings und bieten struktur-extrahierende Einblicke in große Datenmengen für den Nutzer und können eine hilfreiche Vorbereitung der Daten für das Feature Engineering für überwachte Lernverfahren bzw. für deren Trainingsvorgänge darstellen.
Sie möchten erfahren, wie supervised oder unsupervised Machine Learning für Ihre Geschäftsanwendung die richtigen sein könnten? Dann lassen Sie uns sprechen oder nutzen Sie unsere AI Assessment für einen schnellen Einstieg in KI für Ihr Business.
![]() DATANOMIQ ist der herstellerunabhängige Beratungs- und Service-Partner für Business Intelligence, Process Mining und Data Science. Wir erschließen die vielfältigen Möglichkeiten durch Big Data und künstliche Intelligenz erstmalig in allen Bereichen der Wertschöpfungskette. Dabei setzen wir auf die besten Köpfe und das umfassendste Methoden- und Technologieportfolio für die Nutzung von Daten zur Geschäftsoptimierung.
DATANOMIQ ist der herstellerunabhängige Beratungs- und Service-Partner für Business Intelligence, Process Mining und Data Science. Wir erschließen die vielfältigen Möglichkeiten durch Big Data und künstliche Intelligenz erstmalig in allen Bereichen der Wertschöpfungskette. Dabei setzen wir auf die besten Köpfe und das umfassendste Methoden- und Technologieportfolio für die Nutzung von Daten zur Geschäftsoptimierung.