Haben auch Ihre Mitarbeiter bereits mit Python-Skripten erste kleine KI-Anwendungen, beispielsweise eine Bilderkennung oder eine Textklassifikation, programmiert? Dann basieren diese Erfolge vermutlich nicht auf dem Expertenwissen in den Grundlagen des maschinellen Lernens, vielmehr ist der erfolgreiche Einsatz des Transfer Learnings wahrscheinlich. Denn Transfer Learning ermöglicht uns die einfache Wiederverwendung der großen Mühe, die Data Scientists und Datenaufbereiter bereits in KI-Modelle investiert haben, meistens einfach als Download aus dem Internet.
Das Prinzip des Transfer Learnings funktioniert grundsätzlich mit künstlichen neuronalen Netzen, die, auf eine bestimmte Aufgabenstellung ausgerichtet, trainiert werden. Jedes künstliche neuronale Netz ist vereinfacht gesagt nichts weiter als eine Funktion des parametrisierten maschinellen Lernens, deren Koeffizienten-Werte erst durch das Training definiert werden. Die Funktion wird über ein Training mit Daten auf ein bestimmtes Ziel gewissermaßen abgerichtet, beispielsweise auf die Erkennung von bestimmten Wortbedeutungen in Textdaten oder von bestimmten Objekten auf Bildern. Das Training benötigt dabei viele Tausende Iterationen auf Millionen von Datensätzen (Big Data).
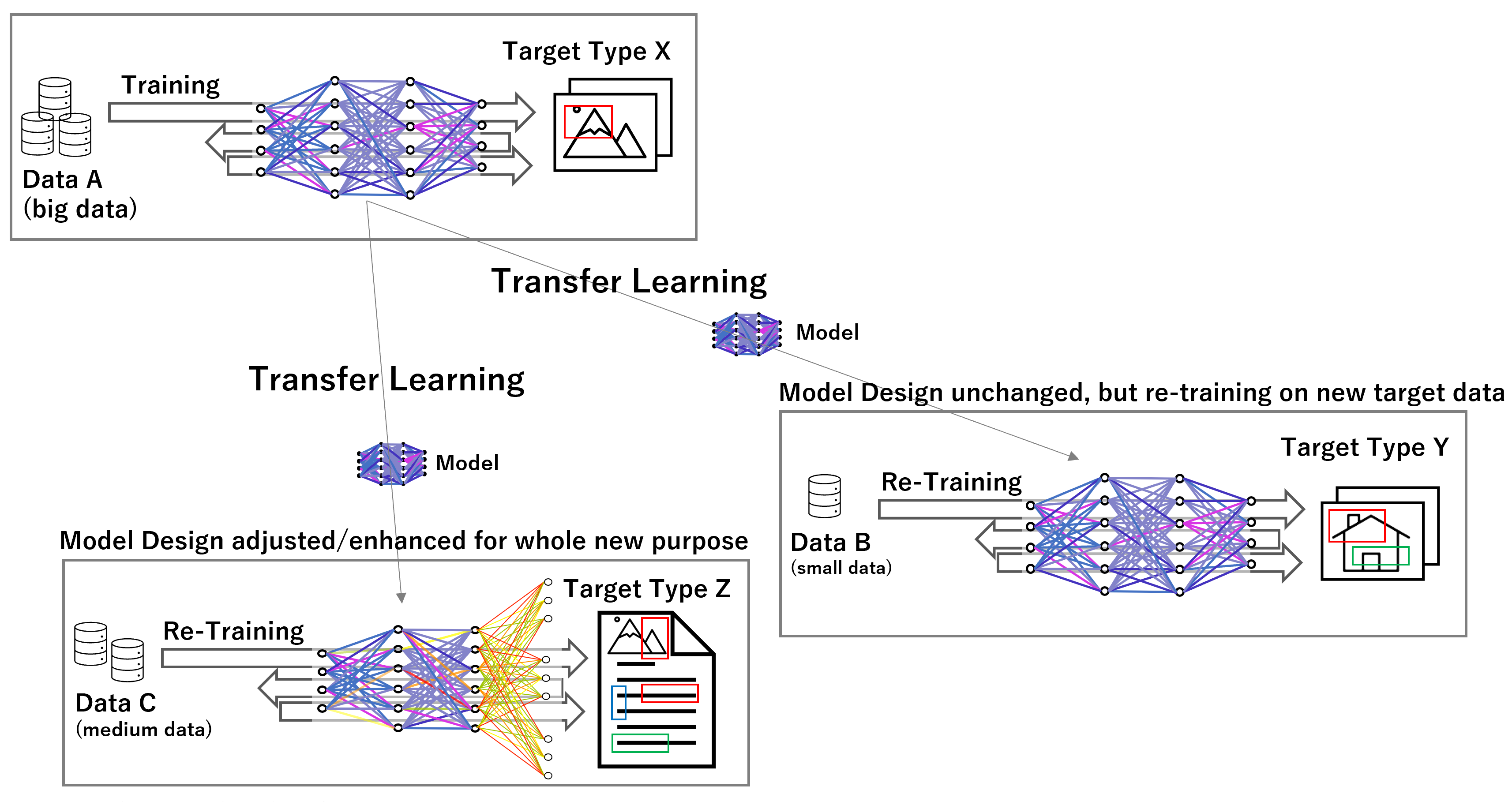
Trainierte Modelle (also Funktionen) können abgespeichert, wieder aufgerufen und sogar nachtrainiert werden. Das nachträgliche Trainieren kann beispielsweise notwendig werden, wenn sie die Datenlage über die Zeit verändert hat oder eben, um ähnliche Aufgabenstellungen mit dem Modell zu bewältigen. Ein neuronales Netz, das beispielsweise Menschen auf Bildern erkennen kann, kann möglicherweise auch humanoide Roboter oder Außerirdische auf Bildern erkennen. Mit einem Nachtraining mit darauf ausgerichteten Daten könnte dies möglich sein, sich das Prädiktionsmodell somit an die neue Aufgabenstellung anpassen. In der Regel sind dafür nur ein Bruchteil der Daten notwendig, die für das ursprüngliche Modell zum Trainieren notwendig waren. Das Nachtraining stellt lediglich ein Update dar.
So richtig von Transfer Learning spricht man aber eigentlich erst dann, wenn das vortrainierte Modell für komplett neue, jedoch artverwandte Aufgabenstellungen quasi aufgebohrt wird. Auch hier erfolgt ein Nachtraining, aber auch eine Anpassung der letzten Schichten in der Netz-Architektur, beispielsweise um mehr Klassen unterscheiden zu können. Da hierdurch das Netz gewissermaßen „Schaden“ nimmt, denn viele Koeffizienten-Werte (Gewichtungen) gehen durch die Anpassung verloren, werden wieder mehr Daten für das Nachtrainung notwendig, jedoch meistens immer noch weniger als für das ursprüngliche Modell notwendig waren. Der Vorteil ist jedoch immens: Erfolgreich vortrainierte KI-Modelle können für neue vergleichbare Anwendungszwecke angepasst und wiederverwendet werden. Das Rad muss also nicht immer neu erfunden oder trainiert werden.
Transfer Learning ermöglicht uns damit die schnellere Entwicklung von KI-Anwendungen, denn nicht nur mit Python-Bibliotheken ausgelieferte vortrainierte Modelle sind sofort einsatzbereit, auch gibt es ganze Community-Plattformen wie https://huggingface.co, die viele vortrainierte Modelle zum Download anbieten.
Aber auch als Grundlage für neue Geschäftsmodelle dient Transfer Learning, denn so können Unternehmen sinnvolle Modelle selbst mit ihren Daten trainieren und diese Modelle dann nicht nur selbst wiederverwenden, sondern auch verkaufen als AI as a Service, mit der Option des Nachtrainierens auf individuelle Daten der Käufer.
Sie interessieren sich für AI as a Service, Daten-Strategien für Ihr Unternehmen oder für ein Data Assessment, bei dem wir Ihrer Daten-Architektur auf den Zahn fühlen? Nutzen Sie unser Kontaktformular oder schreiben Sie uns eine E-Mail an info@datanomiq.de.
![]() DATANOMIQ ist der herstellerunabhängige Beratungs- und Service-Partner für Business Intelligence, Process Mining und Data Science. Wir erschließen die vielfältigen Möglichkeiten durch Big Data und künstliche Intelligenz erstmalig in allen Bereichen der Wertschöpfungskette. Dabei setzen wir auf die besten Köpfe und das umfassendste Methoden- und Technologieportfolio für die Nutzung von Daten zur Geschäftsoptimierung.
DATANOMIQ ist der herstellerunabhängige Beratungs- und Service-Partner für Business Intelligence, Process Mining und Data Science. Wir erschließen die vielfältigen Möglichkeiten durch Big Data und künstliche Intelligenz erstmalig in allen Bereichen der Wertschöpfungskette. Dabei setzen wir auf die besten Köpfe und das umfassendste Methoden- und Technologieportfolio für die Nutzung von Daten zur Geschäftsoptimierung.


