Das wohl bekannteste Datenmodell im Data Warehousing ist das Sternenmodell (Star Schema). Es gibt jedoch umfangreichere und grundlegendere Datenmodelle, die die Datenmodellierung um mehr Möglichkeiten der Repräsentation und flexiblen Erweiterung ergänzen, mit eigenen Vor- sowie Nachteilen: Data Vault 2.0.
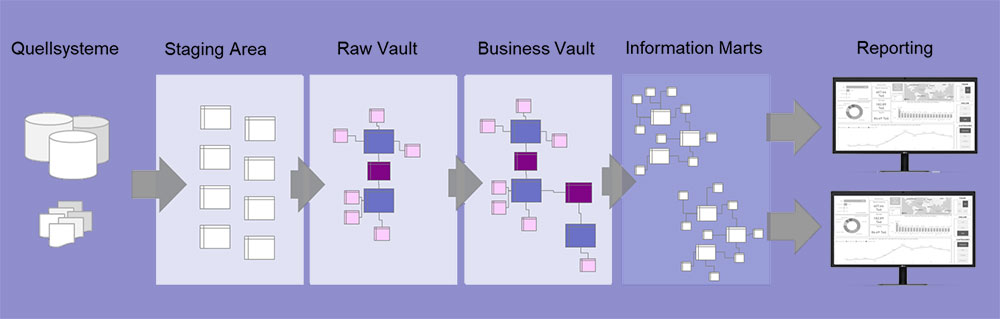
Die Schichten des Data Warehouses:
Die Daten werden zunächst über eine Staging – Area in den Raw Vault geladen.
Bis hierher werden sie nur strukturell verändert, das heißt, von ihrer ursprünglichen Form in die Data Vault Struktur gebracht. Inhaltliche Veränderungen finden erst im Business Vault statt; wo die Geschäftslogiken auf den Daten angewandt werden.
Die Information Marts bilden die Basis für die Reporting-Schicht. Hier müssen nicht unbedingt Tabellen erstellt werden, Views können hier auch ausreichend sein. Hier werden Hubs zu Dimensionen und Links zu Faktentabellen, jeweils angereichert mit Informationen aus den zugehörigen Satelliten.
Was ist eigentlich Data Vault 2.0?
Data Vault 2.0 ist ein im Jahr 2000 von Dan Linstedt veröffentlichtes und seitdem immer weiter entwickeltes Modellierungssystem für Enterprise Data Warehouses.
Im Unterschied zu der Data Warehouse ist ein Data Vault Modell funktionsorientiert über alle Geschäftsbereiche hinweg und nicht themenorientiert. Ein und dasselbe Produkt beispielsweise ist mit demselben Business Key sichtbar für Vertrieb, Marketing, Buchhaltung und Produktion.
Data Vault ist eine Kombination aus Sternschema und dritter Normalform mit dem Ziel, Geschäftsprozesse als Datenmodell abzubilden. Dies erfordert eine enge Zusammenarbeit mit den jeweiligen Fachbereichen und ein gutes Verständnis für die Geschäftsvorgänge.
Die Grundelemente des Data Vault Modells:
Daten werden aus den Quellsystemen in sogenannte Hubs, Links und Satelliten im Raw Vault geladen.
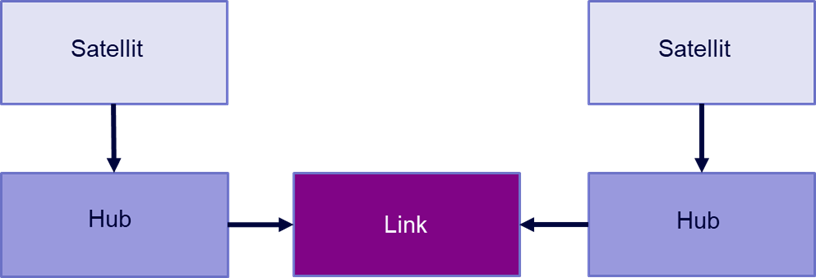
Hub:
Hub-Tabellen beschreiben ein Geschäftsobjekt, beispielsweise einen Kunden, ein Produkt oder eine Rechnung. Sie enthalten einen Business Key (eine oder mehrere Spalten, die einen Eintrag eindeutig identifizieren), einen Hashkey – eine Verschlüsselung der Business Keys – sowie Datenquelle und Ladezeitstempel.
Link:
Ein Link beschreibt eine Interaktion oder Transaktion zwischen zwei Hubs. Beispielsweise eine Rechnungszeile als Kombination aus Rechnung, Kunde und Produkt. Auch ein Eintrag einer Linktabelle ist über einen Hashkey eindeutig identifizierbar.
Satellit:
Ein Satellit enthält zusätzliche Informationen über einen Hub oder einen Link. Ein Kundensatellit enthält beispielsweise Name und Anschrift des Kunden sowie Hashdiff (Verschlüsselung der Attribute zur eindeutigen Identifikation eines Eintrags) und Ladezeitstempel.
Praxisbeispiel Raw Vault Bestellung:
Das Design eines Raw Vault Modells funktioniert in mehreren Schritten:
- Business Keys identifizieren und Hubs definieren
- Verbindungen (Links) zwischen den Hubs identifizieren
- Zusätzliche Informationen zu den Hubs in Satelliten hinzufügen
Angenommen, man möchte eine Bestellung inklusive Rechnung und Versand als Data Vault modellieren.
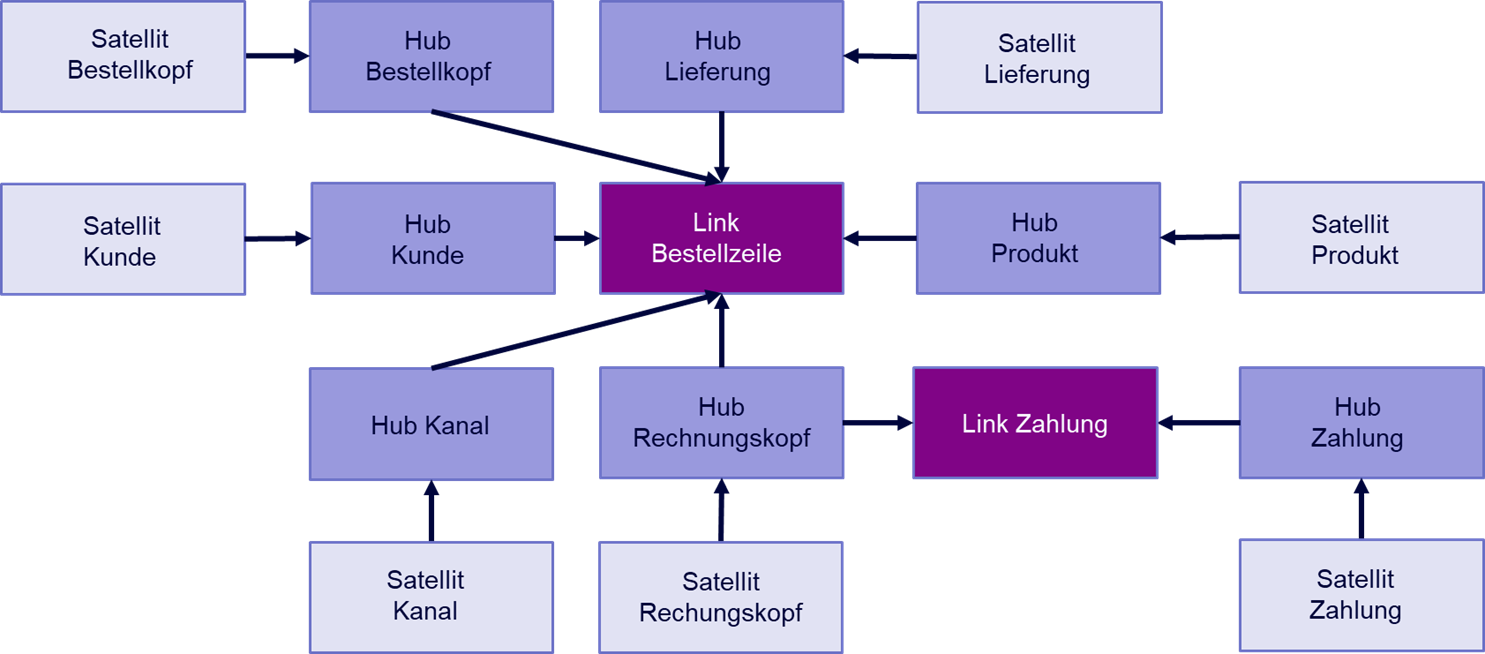
Hubs sind alle Entitäten, die sich mit einer eindeutigen ID – einem Business Key – identifizieren lassen. So erstellt man beispielsweise einen Hub für den Kunden, das Produkt, den Kanal, über den die Bestellung hereinkommt (online / telefonisch), die Bestellung an sich, die dazugehörige Rechnung, eine zu bebuchende Kostenstelle, Zahlungen und Lieferung. Diese Liste ließe sich beliebig ergänzen.
Jeder Eintrag in einem dieser Hubs ist durch einen Schlüssel eindeutig identifizierbar. Die Rechnung durch die Rechnungsnummer, das Produkt durch eine SKU, der Kunde durch die Kundennummer etc.
Eine Zeile einer Bestellung kann nun modelliert werden als ein Link aus Bestellung (im Sinne von Bestellkopf), Kunde, Rechnung, Kanal, Produkt, Lieferung, Kostenstelle und Bestellzeilennummer.
Analog dazu können Rechnung und Lieferung ebenso als Kombination aus mehreren Hubs modelliert werden.
Allen Hubs werden anschließend ein oder mehrere Satelliten zugeordnet, die zusätzliche Informationen zu ihrem jeweiligen Hub enthalten.
Personenbezogene Daten, beispielsweise Namen und Adressen von Kunden, werden in separaten Satelliten gespeichert. Dies ermöglicht einen einfachen Umgang mit der DSGVO.
Herausforderungen bei der Modellierung
Die Erstellung des vollständigen Data Vault Modells erfordert nicht nur eine enge Zusammenarbeit mit den Fachbereichen, sondern auch eine gute Planung im Vorfeld. Es stehen oftmals mehrere zulässige Modellierungsoptionen zur Auswahl, aus denen die für das jeweilige Unternehmen am besten passende Option gewählt werden muss.
Es ist zudem wichtig, sich im Vorfeld Gedanken um die Handhabbarkeit des Modells zu machen, da die Zahl der Tabellen leicht explodieren kann und viele eventuell vermeidbare Joins notwendig werden.
Obwohl Data Vault als Konzept schon viele Jahre besteht, sind online nicht viele Informationen frei verfügbar – gerade für komplexere Modellierungs- und Performanceprobleme.
Anwendungsszenarien für Data Vault
Data Vault als generalistische, dynamische Datenmodellierung wird vor allem für die moderne Business Intelligence angewendet, mit der Möglichkeit, Daten auch für andere Applikationen flexibel bereitstellen zu können. Für Process Mining kann Data Vault 2.0 als Vormodellierung verwendet werden, dynamischere Datenmodelle für Event Logs im Process Mining können auf ähnliche objektorientierte Datenmodellierung nach dem Prinzip der objekt-zentrischen Datenmodellierung (Object-centric Process Mining) erstellt werden.
Für den sehr flexiblen Einsatz der Daten bietet sich diese Datenmodellierung auch insbesondere im Data Mesh in einer Cloud Data Platform an.
Data Vault im Data Lakehouse
Moderne Data Warehouse Projekte wandeln sich zunehmend zu Data Lakehouse Systemen. Data Vault 2.0 kann ein Datenmodellierungskonzept für die Trusted Data Zone des Data Lakehouse Systems sein, ist jedoch nicht die richtige Methode, um auch unstrukturierte Daten zu verarbeiten, was für ein Unternehmen sicherlich das eigentliche Kernargument für ein Data Lakehouse System ist.
Fazit
Data Vault ist ein Modellierungsansatz, der vor allem für Organisationen mit vielen Quellsystemen und sich häufig ändernden Daten sinnvoll ist. Hier lohnt sich der nötige Aufwand für Design und Einrichtung eines Data Vaults und die Benefits in Form von Flexibilität, Historisierung und Nachverfolgbarkeit der Daten kommen wirklich zum Tragen.